
光学式文字認識(OCR)
イントロダクション

OCRを使用したデータ抽出の結果。
光学式文字認識(OCR)は、画像からテキスト情報を抽出する機械ビジョンのタスクです。
OCRの最新技術は、高いテキスト認識の精度と中粒度のグラフィカルノイズへの強さを提供しています。 ドットマトリックスプリンタを使用して作成された文字の認識にも適用できます。この技術は、部分的に遮られたり変形したりした文字に対しても満足のいく結果を提供します。
認識プロセスの効率は、テキストセグメンテーションの結果の品質に大きく依存しています。ほとんどの認識ケースは、提供された一連の認識モデルを使用して行うことができます。他の場合では、新しい認識モデルを簡単に準備することができます。
コンセプト
OCR技術は、さまざまなソースからのデータの自動読み取りに広く使用されています。 主に文書や印刷されたラベルからデータを収集するために使用されています。
このマニュアルの最初の部分では、高レベルのフィルタの使用方法が説明されます。
このマニュアルの2番目の部分では、Aurora Vision Studioで提供されている標準のOCRモデルの使用方法が示されています。 また、認識の最良の結果を得るために画像を準備する方法も説明されています。
3番目の部分では、OCRモデルの準備とトレーニングのプロセスについて説明します。
最後の部分では、画像からテキストを読み取る例のプログラムが紹介されています。
高レベルの光学式文字認識フィルタの使用
Aurora Vision Studioは、画像からテキスト領域を抽出し、それをトレーニングされたOCRクラシファイアで読み取る便利な方法を提供しています。
典型的なOCRアプリケーションは、次の手順で構成されています:
- テキストの位置を検索 – テンプレートマッチングを使用してテキストの位置を特定します。
- テキストの抽出 – フィルタExtractTextを使用してテキストを背景から区別し、セグメンテーションを行います。
- テキストの読み取り – ReadTextフィルタを使用して抽出された文字を認識します。
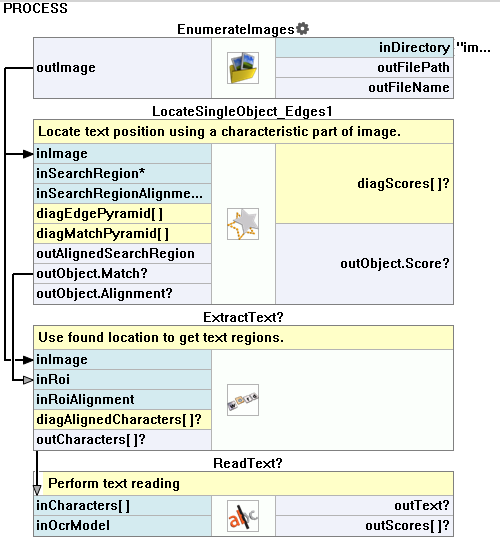
高レベルのフィルタを使用した例のOCRアプリケーション。
Aurora Vision Studioは、OCRプロセスの構成のための便利なグラフィカルツールを提供しています。詳細は以下の記事を参照してください:
光学式文字認識技術の詳細
画像からテキストの読み取り
最も正確な認識を実現するためには、慎重なテキストの抽出とセグメンテーションが必要です。 画像からテキストを取得する全体のプロセスは、以下の手順で構成されています:
以下のセクションでは、画像からテキストを検出および認識するために使用される手法を紹介します。 このガイドをより理解するためには、基本的なブロブ解析技術に精通していることが望ましいです。
テキストの位置取得
一般的に、テキストのローカライゼーションタスクは次の3つのケースに分類できます:
- テキストの位置が固定され、ボックスと呼ばれるマスクで説明されています。
たとえば、個人情報カードは公式の仕様に従って作成されます。
各データフィールドの位置が既知です。
よくキャリブレートされたビジョンシステムは、テキストの位置がほぼ一定である画像を取得できます。

マスクが描かれたサンプル画像。
- テキストの位置は固定されていませんが、入力画像の特徴的な要素または特別なマーカー(光学マーク)に関連しています。 テキストの位置を取得するには、光学マークを見つける必要があります。これはテンプレートマッチング、1Dエッジ検出などで行うことができます。
-
テキストの位置は指定されていませんが、イメージのしきい値処理で文字を背景から簡単に分離できます。
正しい文字はその後、ブロブ解析技術を使用して見つけることができます。

ボトルキャップからテキストを取得する。
テキストの位置が指定された場合、分析対象の画像はテキスト行をX軸に平行にする必要があります。これは、RotateImage、CropImageToRectangle、またはImageAlongPath フィルターを使用して行うことができます。
背景からテキストを抽出する
テキスト抽出の過程での主な複雑さの一つは均一でない光です。 光の正規化やエッジの強調などの手法は、文字を見つけるのに役立ちます。 光の正規化の例は、Examples\Tablets プロジェクトのサンプルで見つけることができます。 フーリエ変換を使用した画像のシャープニングのプレゼンテーションは、Examples\Fourier の例にあります。

元の画像

光の正規化後の画像

フーリエ変換を使用した低周波画像抑制後の画像
テキストの抽出は画像の二値化技術に基づいています。文字を抽出するために、ThresholdToRegion や ThresholdToRegion_Dynamic などのフィルターを使用できます。 文字を含まない領域を認識しないようにするには、ブロブ領域に基づいたフィルターを使用することをお勧めします。
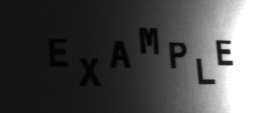



ここで、抽出されたテキスト領域はセグメンテーションの準備が整いました。
テキストのセグメンテーション
テキスト領域のセグメンテーションは、領域を行および個々の文字に分割するプロセスです。 各領域が単一の文字を含む場合にのみ、認識ステップが可能です。
まず、複数行のテキストがある場合は、行への分割を実行する必要があります。テキストの方向が水平の場合、 単純な領域膨張を行った後に領域をブロブに分割することができます。それ以外の場合は、テキストを変換して行が水平になるようにする必要があります。

領域モルフォロジーフィルターを使用してテキストを行に分割するプロセス
テキスト行が分離されたら、各行を個々の文字に分割する必要があります。 濁点や文字がうまく分離できる場合は、フィルターSplitRegionIntoBlobsを使用できます。 それ以外の場合は、フィルターSplitRegionIntoExactlyNCharactersまたは SplitRegionIntoMultipleCharactersを使用する必要があります。


次に、抽出された文字は、グラフィカルな表現からテキスト表現に変換されます。
事前に準備されたOCRモデルの使用
標準のOCRモデルは通常、ディスクディレクトリC:\ProgramData\Aurora Vision\{Aurora Vision Product Name}\PretrainedFontsにあります。
以下のテーブルには使用可能なフォントモデルの一覧が表示されています:
| フォント名 | フォントの書体 | セット名 | 文字 |
|---|---|---|---|
| OCRA | 等幅 | AZ | ABCDEFGHIJKLMNOPQRSTUVWXYZ.-/ |
| AZ_small | abcdefghijklmnopqrstuvwxyz.-/ | ||
| 09 | 0123456789.-/+ | ||
| AZ09 | ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.-/+ | ||
| OCRB | 等幅 | AZ | ABCDEFGHIJKLMNOPQRSTUVWXYZ.-/ |
| AZ_small | abcdefghijklmnopqrstuvwxyz.-/ | ||
| 09 | 0123456789.-/+ | ||
| AZ09 | ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.-/+ | ||
| MICR | 等幅 | ABC09 | ABC0123456789 |
| Computer | 等幅 | AZ | ABCDEFGHIJKLMNOPQRSTUVWXYZ.-/ |
| AZ_small | abcdefghijklmnopqrstuvwxyz.-/ | ||
| 09 | 0123456789.-/+ | ||
| AZ09 | ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.-/+ | ||
| DotMatrix | 等幅 | AZ | ABCDEFGHIJKLMNOPQRSTUVWXYZ+-./ |
| AZ09 | ABCDEFGHIJKLMNOPQRSTUVWXYZ+-01234556789./ | ||
| 09 | 01234556789.+-/ | ||
| Regular | プロポーショナル | AZ | ABCDEFGHIJKLMNOPQRSTUVWXYZ.-/ |
| AZ_small | abcdefghijklmnopqrstuvwxyz.-/ | ||
| 09 | 0123456789.-/+ | ||
| AZ09 | ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.-/+ |
文字認識
Aurora Vision Libraryでは、2つの種類の文字分類器が提供されています:
- 多層パーセプトロン(MLP)に基づく分類器。
- サポートベクターマシン(SVM)に基づく分類器。
これらの分類器はいずれもOcrModel タイプに格納されています。文字領域からテキストを取得するには、以下の画像に示されているRecognizeCharacters フィルターを使用します:
 |
最初で最も重要なステップは、適切な文字の正規化サイズを選択することです。 内部の分類器は、文字を正規化された形式で認識します。 文字の正規化プロセスの詳細については、分類器トレーニングのプロセスを説明するセクションで提供されます。
文字の正規化により、異なるサイズの文字を分類することが可能になります。パラメータ inCharacterSize は、正規化前の文字のサイズを定義します。値が提供されていない場合、サイズは文字の境界ボックスを使用して自動的に計算されます。
| 文字のプレゼンテーション | 正規化後の文字 | 説明 |
|---|---|---|
 |
 |
適切な文字サイズが選択されています。 |
 |
 |
文字のサイズが小さすぎます。 |
 |
 |
文字のサイズが大きすぎて、文字に関する情報が過剰に失われています。 |
次に、文字のソート順を選択する必要があります。デフォルトの順序は左から右です。
入力テキストにスペースが含まれている場合、inMinSpaceWidth の値を設定する必要があります。この値は、スペースが挿入される2つの文字の間の最小距離を示します。
文字の認識は次の情報を提供します:
- 読まれたテキスト(outCharacters)
- 各文字の認識スコアの配列(outScores)
- 各文字の認識候補の配列(outCandidates)
結果の解釈
以下の表は、例の画像から抽出された文字の認識結果を示しています。 未認識の文字は赤で表示されています。
| 元の 文字 |
認識された 文字 |
スコア | 候補者 (文字と正確さ) |
|
|---|---|---|---|---|
| (outCharacters) | (outScores) | (outCandidates) | ||
| E | E | 1.00 | E: 1.00 | |
| X | X | 1.00 | X: 1.00 | |
| A | A | 1.00 | A: 1.00 | |
| M | M | 1.00 | M: 1.00 | |
| P | R | 0.50 | R: 0.90 | B: 0.40 |
| L | L | 1.00 | L: 1.00 | |
| E | E | 1.00 | E: 1.00 | |
この例では、文字 P はトレーニングセットに含まれていませんでした。その結果、OCRモデルはP文字の表現を認識できませんでした。内部の分類器は、最も類似した既知の文字を選択しようとしました。
結果の検証
文字認識プロセスの結果は、基本的な文字列操作フィルターを使用して検証できます。
以下の例では、読み取られたテキストが有効な年の値を含んでいるかどうかを確認する方法を示しています。年の値は2012年よりも大きく(たとえば、この年に製造が始まった場合)、現在の年よりも大きくてはなりません。

短い年の値の検証。 |
この例は、2つのパートで構成されています。最初の部分では、入力文字列がInteger値に変換されます。 2番目の部分では、年数が有効かどうかを確認します。 フィルターParseIntegerを使用して、テキストをIntegerタイプの数値に変換しました。 ParseIntegerはNil値を返す可能性があるため、無効な年数が提供された場合の検証結果を判断するためにMergeDefaultフィルターを使用する必要があります。 次に、年数は式を使用して確認されます。現在の年を取得するために、フィルターCurrentDateTimeが使用されます。すべての条件が満たされれば、検証は通過します。 |
より複雑な検証には、ユーザー定義のフィルターがお勧めです。詳細については、 ユーザーフィルターの作成に関するドキュメント を参照してください。
OCRモデルの準備
OCRモデルは、内部の統計ツールである分類器と、一連の文字データから構成されます。 文字を認識するためには2種類の分類器が使用されます。最初の分類器のタイプは多層パーセプトロン分類器(MLP)に基づいており、 2番目の分類器はサポートベクターマシン(SVM)を使用しています。詳細については、MLP_Initおよび SVM_Initフィルターのドキュメントを参照してください。各モデルは使用前にトレーニングする必要があります。
OCRモデルのトレーニングプロセスは以下のステップから構成されています:
これらのステップが実行されると、モデルは使用準備が整います。
トレーニングデータセットの準備

コンピュータフォントを使用して生成された合成文字。
実際の使用から取得した文字のサンプル。
各分類器には、トレーニングプロセスを開始するための文字サンプルが必要です。 最高の認識精度を得るために、トレーニング文字サンプルは認識に提供されるものとできるだけ類似しているべきです。 サンプル文字を取得するための2つの可能な方法があります:(1)実際の画像から文字を抽出するか、(2)コンピュータフォントを使用して人工的な文字を生成します。
理想的な世界では、モデルは多くの実際のサンプルを使用してトレーニングする必要があります。 ただし、時には十分な実際の文字サンプルを収集することが難しいことがあります。 この場合、文字サンプルは使用可能なサンプルを変形して生成する必要があります。 データセットが十分に大きくないデータセットでトレーニングされた分類器は、同時にわずかに変更された文字を認識できない可能性があります。
新しい文字サンプルを作成するために使用される例の操作:
- 領域の回転(RotateRegionフィルターの使用)、
- せん断(ShearRegion)、
- 膨張と収縮(DilateRegion、ErodeRegion)、
- ノイズの追加。

領域の回転、形態学的変形、せん断、ノイズによって変形した文字サンプルのセット。
注意:トレーニングセットにあまりにも多くの変形した文字を追加すると、モデルのトレーニング時間が増加します。
注意:文字の形状を過度に変形させると、分類器が学習した文字ベースを認識できなくなる可能性があります。たとえば、トレーニングセットにC文字が多すぎるノイズを含んでいる場合、O文字と誤認識される可能性があります。この場合、分類器は新しく提供された文字のベースを決定できません。
各文字サンプルはCharacterSample型の構造に格納する必要があります。この構造は文字領域とそのテキスト表現から構成されます。文字サンプルの配列を作成するにはMakeCharacterSamplesフィルターを使用します。
正規化サイズと文字の特徴の選択
文字の正規化は、文字分類に使用されるデータの量を減少させることを可能にします。正規化のもう一つの目的は、分類プロセスがさまざまなサイズの文字を認識できるようにすることです。
正規化中に、各文字はモデルの初期化時に提供されたサイズにリサイズされます。 その後のすべての分類器操作は、リサイズされた(正規化された)文字で実行されます。

正規化プロセス前後のさまざまなサイズの文字。
大きすぎる正規化サイズを選択すると、OCR分類器のトレーニング時間が増加します。 一方、サイズが小さすぎると、重要な文字の詳細が失われます。 選択した正規化サイズは、分類時間と認識の精度の間の妥協であるべきです。最良の結果を得るためには、正規化後の文字サイズは、正規化前のサイズと類似しているべきです。
正規化プロセス中には、文字のアスペクト比などの一部の詳細が失われます。 トレーニングプロセスでは、正規化プロセスでの情報損失を補償できるいくつかの追加情報が追加できます。詳細については、TrainOcr_MLPフィルターのドキュメントを参照してください。
OCRモデルのトレーニング
各タイプのOCR分類器をトレーニングするためには、2つのフィルターが使用されます。これらのフィルターには、分類器のトレーニングプロセスを説明するパラメータが必要です。
 |
 |
| TrainOcr_MLPを使用したMLP分類器のトレーニング。 | TrainOcr_SVMを使用したSVM分類器のトレーニング。 |
トレーニング結果の保存
分類器のトレーニングが成功したら、結果は将来の使用のために保存する必要があります。 フィルターSaveObjectを使用する必要があります。
例: マスクから数字を読み取る
この例の目的は、IDカードからフィールドを読み取ることです。入力データは実際のケースから抽出されています。この例は、次の2つの部分で構成されています:
- 「TrainCharacters」マクロフィルタで分類器のトレーニングデータセットを作成する部分。
- このマクロフィルタは、提供されたマスクからデータを取得するためのもので、"Main" マクロフィルタで実装されています。
この例プロジェクトは、Examples\Ocr Read Numbersディレクトリで利用可能です。
分類器のトレーニング
|
最初に、このフィルタ LoadImage は個別のファイルから文字画像を読み込みます。ファイル名は グローバルパラメータ である FileNames に格納されています。 |

OCRのトレーニングを実行するマクロフィルタの定義。 |
画像からデータを読み取る

トレーニングされた分類器を使用して画像からテキストを取得するマクロフィルタ。 |
最初に、例の画像がファイルから読み込まれます。 |