
ディープラーニング
目次:
1. はじめに
ディープラーニングは、コンピュータビジョンにおける画期的な機械学習技術です。 ユーザーが提供したトレーニング画像から学習し、様々な画像解析アプリケーションに対する解決策を自動的に生成できます。 しかし、その主な利点は、過去の伝統的なルールベースのアルゴリズムでは難しかった多くのアプリケーションを解決できることです。 特に、これには形状や外観の変動が大きいオブジェクトの検査、有機製品などが含まれます。 また、当社のAurora Vision Deep Learningなどの既製品を使用する場合、必要なプログラミングの労力はほぼゼロにまで減少します。 一方で、ディープラーニングはデータとの作業に焦点を当て、高品質な画像の注釈作業やトレーニングパラメータの実験などが、実際にはほとんどのアプリケーション開発時間を占める傾向があります。
典型的なアプリケーションは以下の通りです:
- 表面および形状の欠陥の検出(クラック、変形、変色など)、
- 異常または予想外のサンプルの検出(欠落、破損、品質の低い部品など)、
- 事前定義されたクラスに対するオブジェクトまたは画像の識別(ソーティングマシンなど)、
- 画像内の複数のオブジェクトの位置、セグメンテーション、分類(ビンピッキングなど)、
- 製品品質分析(果物、植物、木材などの有機製品を含む)、
- キーポイント、特徴領域、小物体の位置と分類、
- 光学文字認識。
ディープラーニングの機能の使用には、次の2つのステージがあります:
- トレーニング - トレーニングサンプルから学習した特徴に基づいてモデルを生成する、
- 推論 - モデルを新しい画像に適用して実際のマシンビジョンタスクを実行する。
伝統的な画像解析アプローチとの違いは、以下の図に示されています:
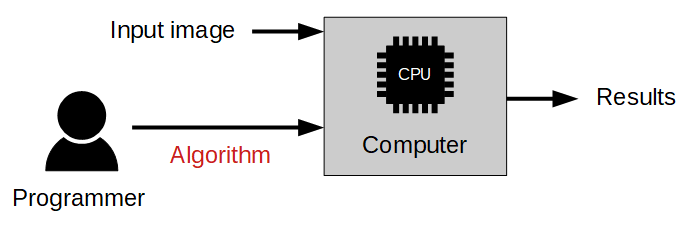
伝統的なアプローチ
アルゴリズムは人間の専門家によって設計される必要があります。
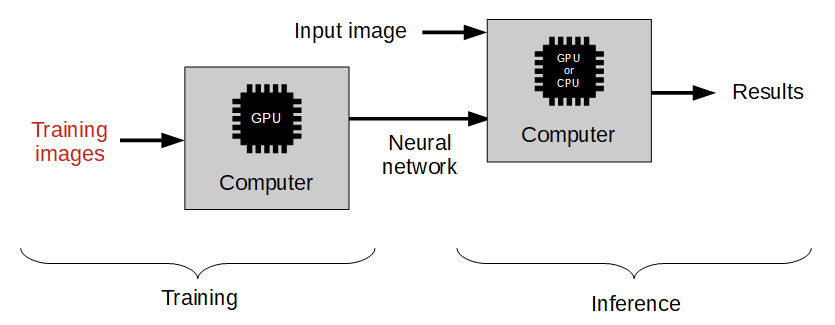
機械学習アプローチ
ラベル付き画像のトレーニングセットを提供するだけで良いです。
ディープラーニングツールの概要
| 異常検知 | この手法は、異常(異常または予期せぬ)サンプルを検出するために使用されます。通常の外観のモデルを学習するために、故障のないサンプルセットのみが必要です。 オプションで、許容できる変動の閾値をよりよく定義するためにいくつかの故障サンプルを追加できます。このツールは特に、すべての可能な欠陥の種類を指定するのが難しい場合や、ネガティブサンプルが単に利用できない場合に有用です。このツールの出力は、分類結果(正常または故障)、異常スコア、および画像内の(粗い)異常ヒートマップです。 |

DL_DetectAnomalies2ツールを使用した欠落オブジェクトの検出の例。 |
|---|---|---|
| 特徴検出(セグメンテーション) | この手法は、画像内のピクセル単位の特徴の1つまたは複数のクラスを正確にセグメントするために使用されます。各クラスに属するピクセルは、トレーニングステップでユーザーによってマークされる必要があります。この手法の結果は、各クラスに対する確率マップの配列です。 |
 DL_DetectFeaturesツールを使用した画像セグメンテーションの例。 |
| 物体分類 | この手法は、選択した領域内のオブジェクトをユーザー定義のクラスの1つで識別するために使用されます。 まず、ラベル付きの画像のトレーニングセットを提供する必要があります。この手法の結果は、検出されたクラスの名前と分類の信頼レベルです。 |

DL_ClassifyObjectツールを使用したオブジェクト分類の例 |
| インスタンスセグメンテーション | この手法は、画像内の1つまたは複数のオブジェクトを位置付け、セグメントし、分類するために使用されます。 トレーニングでは、ユーザーは画像内のオブジェクトに対応する領域を描画し、それらをクラスに割り当てる必要があります。結果は、検出されたオブジェクトのリストです – バウンディングボックス、マスク(セグメント化された領域)、クラスID、名前、およびメンバーシップ確率が含まれています。 |

DL_SegmentInstancesツールを使用したインスタンスセグメンテーションの例。左: 元の画像。 右: 検出されたオブジェクトのリスト |
| ポイント位置 | この手法は、画像内のキーポイント、特徴的な部分、および小さなオブジェクトを正確に位置付け、分類するために使用されます。 トレーニングでは、ユーザーはトレーニング画像上で適切なクラスのポイントをマークする必要があります。結果は、予測されたポイントの位置のリスト と対応するクラスの予測と信頼スコアです。 |

DL_LocatePointsツールを使用したポイント位置の例。 |
| 文字認識 | この手法は、画像内の文字を位置付けて認識するために使用されます。結果は、検出された文字のリストです。 |

DL_ReadCharactersツールを使用した光学文字認識の例。 |
基本用語
ディープラーニングソリューションを開発するためには、特別な科学的知識が必要ではありません。ただし、プロセスの背後にある基本的な用語と原則を理解することが強くお勧めされます
ディープニューラルネットワーク
Aurora Visionは、産業用マシンビジョンのタスクを解決するために作成、調整、テストされたいくつかの標準化されたディープニューラルネットワークアーキテクチャにアクセスできます。各ネットワークは、トレーニング可能な畳み込みフィルターとニューラルコネクションのセットであり、画像の複雑な変換をモデル化し、関連する特徴を抽出して特定の問題を解決するために使用できます。ただし、これらのネットワークは、トレーニングプロセスに適切な量の高品質なデータが提供されなければ役立ちません。このドキュメントでは、効果的なディープラーニングモデルを作成するための実践的なヒントを提供しています。
ニューラルネットワークの深さ
タスクの複雑さの異なるレベルと異なる実行時間の期待値により、ユーザーは5つの利用可能なネットワークの深さから選択できます。 ネットワークの深さパラメータは、ニューラルネットワークのメモリ容量(つまり、層とフィルターの数)とより複雑な問題を解決する能力を定義する抽象的な値です。以下のリストは、タスクの特性と条件に適切な深さを選択するためのヒントを示しています。
-
低い深さ(値1-2)
- 問題が簡単に定義できる。
- 人間の検査員が簡単に解決できる問題。
- 実行には短い時間が必要。
- 画像間で背景と照明が変わらない。
- オブジェクトは適切に配置され、画像の品質が良好。
-
標準の深さ(デフォルト、値3)
- 特別な条件がない場合に適しています。
- 現代のCUDA対応のGPUが利用可能。
-
高い深さ(値4-5)
- 大量のトレーニングデータが利用可能。
- 問題が難しくまたは非常に複雑で定義および解決が難しい。
- 画像全体で複雑な不規則なパターン。
- トレーニングおよび実行に長い時間がかかっても問題ない。
- 大量のGPU RAM(≥4GB)が利用可能。
- 背景、照明、またはオブジェクトの配置が異なる。
ヒント:必要に応じて、最初に低い深さでソリューションをテストし、それを増やしてみてください。
注意:ネットワークの深さを増やすと、トレーニングおよび実行のメモリおよび計算の複雑性が著しく増加します。
トレーニングプロセス
モデルのトレーニングは、トレーニングデータに基づいてニューラルネットワークの重みを更新する反復プロセスです。1つの イテレーション はいくつかのステップ(自動的に決定される)から成り、各ステップは次の操作を含みます:
- トレーニングサンプルの小さなサブセット(バッチ)の選択
- これらのサンプルの誤差メジャーの計算
- これらのサンプルの誤差を低減させるための重みの更新
各イテレーションの終わりに、現在のモデルはトレーニングプロセスの前に選択された別の検証サンプルセットで評価されます。検証セットはトレーニングサンプルから自動的に選択されます。これは、ニューラルネットワークがトレーニング中に使用されなかった実際の画像とどのように動作するかを模倣するために使用されます。 トレーニングの最後に検証スコアが最も良いネットワークの重みセットのみが最終的なソリューションとして保存されます。 連続したイテレーションでのトレーニングおよび検証スコア(以下の図の青およびオレンジの線)を監視することは、進捗に関する基本的な情報を提供します:
- トレーニングおよび検証スコアが改善している – トレーニングを続け、モデルはまだ改善できます。
- トレーニングおよび検証スコアが改善していない – トレーニングをさらに数イテレーション行い、まだ変化がない場合は停止します。
- トレーニングスコアが改善しているが、検証スコアが停止または悪化している – トレーニングを停止できます。モデルはおそらくトレーニングデータに過剰適合し始めています(特定のサンプルを覚えているのではなく、特徴に関する規則を学んでいる)。これは、多様なサンプルが少なすぎるか、選択されたネットワークの問題の複雑さが低すぎる場合にも起こり得ます(Network Depthを低くしてみてください)。

正しいトレーニングの例 |
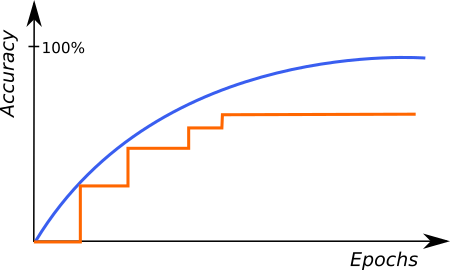
ネットワークの過剰適合の特徴的なグラフ |
上記のグラフは、Deep Learning Editorでのトレーニングの進捗を表しています。青の線はトレーニングサンプルのパフォーマンスを示し、オレンジの線は検証サンプルのパフォーマンスを表します。検証パフォーマンスはイテレーションの最後でのみ確認されるため、青い線がオレンジの線よりも頻繁にプロットされていることに注意してください。
停止条件
ユーザーは、停止 ボタンをクリックすることでトレーニングを手動で停止できます。また、1つまたは複数の停止条件も設定できます:
- イテレーション数 – 固定されたイテレーション数後にトレーニングが停止します。
- 改善のないイテレーション – 最良の検証スコアが一定のイテレーション数で改善されない場合にトレーニングが停止します。
- 時間 – 一定の分数が経過するとトレーニングが停止します。
- 検証精度 または 検証エラー – 検証スコアが指定された値に達した場合にトレーニングが停止します。
前処理
特定のタスクに性能を調整するために、ユーザーはトレーニングが始まる前に入力画像にいくつかの追加の変換を適用できます:
- ダウンサンプル – 画像サイズを縮小してトレーニングおよび実行時間を加速させるが、検出可能な詳細レベルを低下させる代わりに。このパラメータを1増やすと、画像の両寸法で2倍にダウンサンプリングされます。
- グレースケールに変換 – 色が重要でない問題に対処する際に、画像のモノクロバージョンで作業することができます。
データ拡張
トレーニング画像の数がサンプルのすべての可能な変化を表現するのに十分でない場合は、トレーニング中に人工的に変更されたサンプルを追加するためにデータ拡張を使用することをお勧めします。このオプションは過学習を回避するのにも役立ちます。
以下は利用可能なデータ拡張の説明と対応する変換の例です:
| 輝度 | サンプルの輝度をランダムな割合(-ParameterValueから+ParameterValueまで)でピクセル値(0-255)に変更します。指定された拡張値の場合、以下のようなサンプルがトレーニングセットに追加されます。 |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise | サンプルに一様ノイズを加えます。各チャンネルとピクセルの値は、ピクセル値(0-255)のランダムな割合(-ParameterValueから+ParameterValueまで)によって個別に変更されます。 適切な拡張値を選択する際には、特徴のサイズ(ピクセル単位)に依存すべきです。大きな値は、小さなオブジェクトに対しては大きな影響を与えます。指定された拡張値の場合、以下のような特徴 "F" サイズが 130x130 ピクセルのタイルにトレーニングセットに追加されます。 |
|
||||||||||
| Gaussian Blur | カーネルサイズを 0 から提供された最大カーネルサイズまでランダムに選択してサンプルをぼかします。適切なガウシアンブラーカーネルサイズを選択する際には、特徴のサイズ(ピクセル単位)に依存すべきです。 大きなカーネルサイズは、小さなオブジェクトに対しては大きな影響を与えます。指定された拡張値の場合、以下のような特徴 "F" サイズが 130x130 ピクセルのタイルにトレーニングセットに追加されます。 |
|
||||||||||
| Rotation | サンプルを -ParameterValue から +ParameterValue までのランダムな角度で回転させます。角度の単位は度です。 Detect Features、Locate Points、Detect Anomaliesでは、特徴 "F" が含まれるタイルと指定された拡張値の場合、以下のようなサンプルがトレーニングセットに追加されます。 |
|
||||||||||
| Classify ObjectとSegment Instancesでは、特徴 "F" が含まれる画像と指定された拡張値の場合、以下のようなサンプルがトレーニングセットに追加されます。 |
|
|||||||||||
| Flip Up-Down | サンプルをX軸を中心に反射します。 |
|
||||||||||
| Flip Left-Right | サンプルをY軸を中心に反射します。 | |||||||||||
| Relative Translation | サンプルをランダムなシフトで移動させ、Detect Features、Locate Points、Detect Anomaliesではタイルのサイズのパーセンテージ(-ParameterValue から +ParameterValue)、Classify ObjectおよびSegment Instancesでは画像サイズのパーセンテージ(-ParameterValue から +ParameterValue)で定義されます。XおよびYの両方の寸法で独立して機能します。 Detect Features、Locate Points、Detect Anomaliesでは、特徴 "F" が含まれるタイルと指定された拡張値の場合、以下のようなサンプルがトレーニングセットに追加されます。 |
|
||||||||||
| Classify ObjectおよびSegment Instancesでは、特徴 "F" が含まれる画像と指定された拡張値の場合、以下のようなサンプルがトレーニングセットに追加されます |
|
|||||||||||
| Scale | サンプルを、提供された最小スケールと最大スケールの間のランダムなパーセンテージで元のサイズに対してリサイズします。 |
|
||||||||||
| 水平せん断 | ParameterValue から +ParameterValue の範囲でサンプルを水平にせん断します。角度単位で表されます。 特徴を検出する」「ポイントを特定する」「異常を検出する」の場合、特徴 "F" を持つタイルと指定された拡張値に対して、以下のようなサンプルがトレーニングセットに追加されます。 |
|
||||||||||
| 「オブジェクトを分類する」および「インスタンスをセグメンテーションする」の場合、特徴 "F" を持つ画像と指定された拡張値に対して、以下のようなサンプルがトレーニングセットに追加されます。 |
|
|||||||||||
| 垂直せん断 | 水平せん断と同様の操作です。 「特徴を検出する」「ポイントを特定する」「異常を検出する」の場合、特徴 "F" を持つタイルと指定された拡張値に対して、以下のようなサンプルがトレーニングセットに追加されます。 |
|
||||||||||
| 「オブジェクトを分類する」および「インスタンスをセグメンテーションする」の場合、特徴 "F" を持つ画像と指定された拡張値に対して、以下のようなサンプルがトレーニングセットに追加されます。 |
|








































注意: 拡張オプションの選択は解決したい課題にのみ依存します。時折、これらは解決策の品質に有害である可能性があります。例えば、回転が本番環境で予想されない場合は、回転を有効にしないでください。拡張を有効にすると、ネットワークのトレーニング時間が増加しますが、実行時間には影響しません
2. 異常検出
Aurora Vision Deep Learningでは、欠陥検出の3つの方法が提供されています:
- DL_DetectAnomalies1
- DL_DetectAnomalies2 シングルクラス
- DL_DetectAnomalies2 ゴールデンテンプレート
DL_DetectAnomalies1(再構築アプローチ)は、深層ニューラルネットワークを使用して、入力画像から欠陥を取り除く手法です。影響を受けた領域を再構築します。
このアプローチは、Feature Sizeパラメータで決まる断片のサイズで画像を分析するために使用されます。再構築された欠陥のない画像と元の画像を比較することに基づいています。
Feature Sizeより小さいすべてのパターンを除外し、トレーニングセットに存在しなかったものをフィルタリングします。
DL_DetectAnomalies2 シングルクラス は、ゴールデンテンプレートよりも簡単なアルゴリズムを使用します。使用するスペースが少なく、反復時間が短いです。より複雑なオブジェクトに使用できます。
DL_DetectAnomalies2 ゴールデンテンプレート は、複雑な詳細を持つ位置決めの必要なオブジェクトに適したメソッドです。ツールは画像を領域に分割し、各領域に対して別々のモデルを作成します。 ツールにはテクスチャ欠陥検出用のテクスチャモードがあります。平らな表面または単純なパターンを持つ表面に使用できます。
要約すると、異常検出のためのツールを選択する際には、まずオブジェクトの種類に応じてテクスチャモードをオンまたはオフにしてゴールデンテンプレートを確認してください。 モデルが大きすぎるか、反復が長すぎる場合は、シングルクラスツールを試してみてください。オブジェクトが複雑で位置が安定していない場合は、DL_DetectAnomalies1アプローチを確認してください。

テクスチャ欠陥検出を使用した織物欠陥検出の例:DL_DetectAnomalies2
パラメータ
- Feature Size は DL_DetectAnomalies1 および DL_DetectAnomalies2 Single Class アプローチに関連しています。
これは期待される欠陥のサイズに対応し、検査の品質と速度の両方において最も重要です。
これはエディタのイメージウィンドウにおいて緑の正方形で表されます。
すべての断片ベースのアプローチの共通の要素は、「Feature Size は一般的な欠陥をある程度の余裕で含むように調整されるべきである」という点です。
DL_DetectAnomalies1 の場合、大きな Feature Size は小さな欠陥が無視される可能性がありますが、推論時間がかなり短縮されます。 ヒートマップの精度も低下します。 DL_DetectAnomalies2 の Single Class の場合、大きな Feature Size はトレーニングおよび推論時間、メモリ要件を増加させます。 Feature Size を増やす代わりに Downscale パラメータを使用することを検討してください。 - Sampling Density は DL_DetectAnomalies1 および DL_DetectAnomalies2 Single Class アプローチに関連しています。 これはトレーニングおよび検査の空間的な解像度を制御します。密度が高いほど精密な結果が得られますが、計算時間がかかります。 Low density は位置がよく単純なオブジェクトにのみ適しています。 High density は複雑なテクスチャや高度に変動するオブジェクトと一緒に使用すると役立ちます。
- Max Translation は DL_DetectAnomalies2 Golden Template アプローチに関連しています。 これは最大位置変更の許容度です。パラメータを増やすと、小さなモデルの作業領域が拡大し、作成される小さなモデルの数が減少します。
- Model Complexity は DL_DetectAnomalies2 Golden Template および DL_DetectAnomalies2 Texture アプローチに関連しています。 大きな値はモデルの効果を向上させる可能性がありますが、メモリ使用量と推論時間が増加します。 特に複雑なオブジェクトに対して効果的かもしれませんが、その代償としてメモリ使用量と推論時間が増加します。
メトリクス
異常検出ツールの精度を測定するのは難しいタスクです。最も直接的なアプローチは、画像全体に対して(異常の位置を見ないで)Recall/Precision/F1のメジャーを計算することです。 ただし、このアプローチはいくつかの理由により非常に信頼性が低いです。理由には次のものが含まれます: (1) テスト画像が限られている場合(たとえば20枚)、1つのケースが変わるだけでスコアが大きく変動します(Δ=5%など); (2) テストしたツールは非常に頻繁にランダムな誤検出を行い、正しいものを見つけることができない場合がありますが、それでも画像全体が正しく分類されたと見なされます。 そのため、注釈付きの異常領域を使用し、ピクセルごとのスコアを計算することが誘惑されるかもしれませんが、これは細かすぎます。 異常検出のタスクでは、ツールが欠陥の位置について非常に正確である必要はありません。 個々のピクセルはあまり重要ではありません。代わりに、異常が「だいたい」正しい場所で検出されることを期待しています。 実際、一般に精度があまり高くない(特にオートエンコーダに基づくもの)ツールでも、見つけた欠陥の輪郭は比較的正確になることがあります。 一方で、一クラス分類に基づく方法は一般的にはより良いパフォーマンスを発揮しますが、生成される輪郭はぼやけていたり、細すぎたり、太すぎたりすることがよくあります。
これらの理由から、Recallの計算にはピクセルごとまたは画像ごとのメソッドではなく、領域ごとのアプローチを導入しました。 Recallを計算する方法は次のとおりです:
- 各異常領域に対して、ヒートマップのしきい値を超える単一のピクセルがあるかどうかを確認します。あればTP(真陽性の数)を1増やします。それ以外の場合、FN(偽陰性の数)を1増やします。
- 次に、次の式を使用します:$$ {Recall = \frac{TP}{TP + FN} } $$
上記の手法はRecallに適していますが、Precisionの計算には直接適用できません。そのため、Precisionではピクセルごとのアプローチを使用しますが、これにも困難が伴います。最初の問題は、良いサンプルが多く、テストケースが非常に限られていることがよくあります。これはバランスのとれていないテストデータを意味し、それによりPrecisionメトリックは良いサンプルの圧倒的な量に強く影響されます。GOODサンプルが多いほど(BADサンプルの量が同じである場合)、Precisionは低くなります。実際には非常に低くなることがあり、ツールの実際のパフォーマンスを正確に反映していないことがよくあります。そのため、メトリクスにはバランスを組み込む必要があります。
Precisionに関する実世界のプロジェクトでの2番目の問題は、偽陽性が自然にBAD画像内で発生する傾向があることです。これはいくつかの理由で起こりますが、異なるプロジェクト間で繰り返されます。欠陥がある場合、それは何かが壊れたことを意味し、オブジェクトの他の部分もわずかに影響を受けることがしばしばあります。時にはそれが目に見える方法で、時には曖昧なレベルで発生します。そして、検査対象のオブジェクトは、欠陥を人工的に導入するプロセスに影響を受けることがよくあります(例えば、誰かが布の一部に触れて通常発生しないしわを作り出すなど)。このため、False Negativesのピクセルごとの計算はGOOD画像のみで行います。
Precisionの計算手順は次のとおりです:
- すべてのBADテストサンプルにわたる平均のpp_TP(ピクセルごとの真陽性の数)を計算します。
- すべてのGOODテストサンプルにわたる平均のpp_FP(ピクセルごとの偽陽性の数)を計算します。
- 次に、次の式を使用します:$${Precision=\frac{\overline{pp\underline{}TP} }{\overline{pp\underline{}TP} + \overline{pp\underline{}FP} } }$$
最後に、RecallとPrecisionの値が異なる方法で計算されたことを無視して、標準的な方法でF1スコアを計算します。 これは実用的なアプリケーションに最適なメトリクスだと考えています。
モデルの使用
異常検出1のバリアントでは、モデルはDL_DetectAnomalies1_Deployを使用して実行する前にロードする必要があります。代替として、モデルはDL_DetectAnomalies1フィルターで直接ロードできますが、初めてのプログラムのイテレーションで時間のかかる初期化が必要です。


異常検出2のバリアントでは、モデルはDL_DetectAnomalies2_Deployを使用して実行する前にロードする必要があります。代替として、モデルはDL_DetectAnomalies2フィルターで直接ロードできますが、初めてのプログラムのイテレーションで時間のかかる初期化が必要です。


Aurora Vision Deep Learning Serviceをこれらのフィルターと同時に実行することはお勧めできません。性能の低下やエラーの原因となる可能性があります。
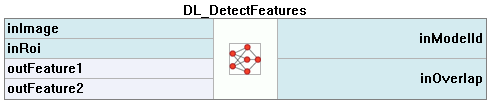
3. 特徴検出(セグメンテーション)
この手法は、欠陥または画像の特徴に対応するピクセル単位の領域を検出するために使用されます。特徴は、例えば衛星画像の道路や表面の特徴的なパターンを持つオブジェクトの一部のようなものでもあります。これは時にはピクセルラベリングとも呼ばれますが、それぞれのピクセルにクラスラベルを割り当てるものであり、オブジェクトのインスタンスを分離しません。
トレーニングデータ
DL_DetectFeaturesのエディタに読み込まれる画像は異なるサイズであり、異なるROIが定義されている場合があります。ただし、スケールと特徴の特性が本番環境と一致していることを確認することが重要です。
特徴は、エディタ内の直感的なインターフェースを使用してマークするか、ファイルからマスクとしてインポートすることができます。
すべてのトレーニング画像で各特徴をマークするか、ROIをマークされた欠陥のみを含むように制限する必要があります。不完全または一貫性のないマークが、精度が低い原因の1つです。覚えておいてください:少しでも何かの特徴をマークし忘れると、それは負のサンプルとして使用され、トレーニングプロセスを非常に混乱させる可能性があります!
マーキングの精度は、アプリケーションの要件に合わせて調整する必要があります。マーキングが正確であれば、本番環境での精度が向上します。低精度でマーキングする場合は、いくらか余分なマージンを持たせて特徴をマークすると良いです。

低い精度でマークされた木の節の例 |

高い精度でマークされたタイルのひび割れの例 |
複数クラスの特徴
1つのモデルを使用して異なるクラスの特徴を別々に検出することが可能です。たとえば、以下の画像のように、道路と建物を検出することができます。異なる特徴は重なることがありますが、通常は推奨されません。また、1つのモデルで複数の異なるクラスを定義することはお勧めされません。一方で、互いに混乱する可能性がある2つの特徴がある場合(例:道路と川)、それらに対して個別のクラスを持ち、それらをマークすることが推奨されます。混乱する特徴がはっきりとマークされている場合(単なる背景として残されていない場合)、ニューラルネットワークは誤分類を防ぐためによりよく機能します。

1つの画像で2つの異なるクラス(赤い道路と黄色い建物)をマークする例。
パッチサイズ
Detect Featuresは、中程度のサイズの正方形ウィンドウで画像を分析する際に最適な動作をするエンドツーエンドのセグメンテーションツールです。このウィンドウのサイズは、パッチサイズパラメータによって定義されます。これは小さすぎず、大きすぎずであるべきです。通常、特徴自体のサイズ(幅または直径)よりもはるかに大きく、画像全体よりもはるかに小さいです。通常、値96または128がかなり適しています。
パフォーマンスのヒント1:大きなパッチサイズはトレーニング時間を増加させ、より多くのGPUメモリとトレーニングサンプルが効果的に操作されるのを必要とします。パッチサイズが128ピクセルを超え、まだ小さすぎると見える場合は、Downsampleオプションを検討する価値があります。
パフォーマンスのヒント2:実行時間が満足いくものでない場合、inOverlapフィルター入力をFalseに設定できます。これにより、より高速な検査が可能になり、精度が低下します。
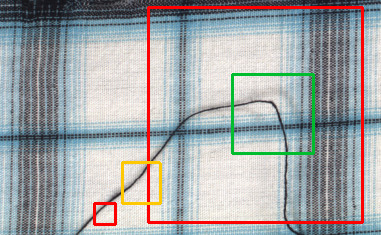
パッチサイズの例:大きすぎるか小さすぎる(赤)、許容できるかもしれない(黄)、良好(緑)。これは単なる例であり、他のケースでは異なる場合があります。
モデルの使用
特徴のセグメンテーションを実行する前に、DL_DetectFeatures_Deployフィルターを使用してモデルをロードする必要があります。代替として、モデルはDL_DetectFeaturesフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。

これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するには、inRoi入力を使用できます。
- 特徴のセグメンテーションプロセスを短縮するには、inOverlapオプションを無効にできます。ただし、ほとんどの場合、これによりセグメンテーションの品質が低下します。
- 特徴のセグメンテーションの結果は、配列としてoutHeatmaps出力に渡され、outFeature1、outFeature2、outFeature3およびoutFeature4は別々の画像として提供されます。
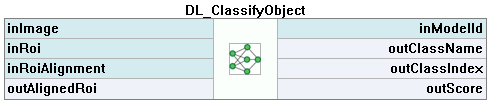
4. オブジェクト分類
この技術は、画像または指定された領域内のオブジェクトのクラスを識別するために使用されます。
動作の原理
トレーニングフェーズでは、オブジェクト分類ツールはユーザーが定義したクラスの表現を学習します。モデルはトレーニング用に提供されたサンプルから得られた一般的な知識を使用し、クラス間の良好な分離を目指します。
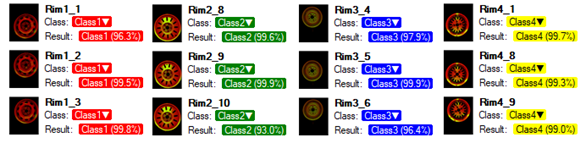
トレーニング後の分類の結果。
トレーニングプロセスが完了すると、ユーザーには混同行列が表示されます。これは、モデルがユーザーが定義したクラスをどれだけうまく分離したかを示します。特に多くのサンプルが使用された場合、モデルの精度を特定するのを簡略化します。

混同行列は、サンプルがユーザーが定義したクラスに正しく(対角線上)または不正確に割り当てられたかを示します。
トレーニングパラメータ
すべてのDeep Learningアルゴリズムで使用可能なパラメータのリストに加えて、DL_ClassifyObjectツールは特定の分類タスクに必要な詳細レベルを制御する詳細レベルパラメータを提供します。ほとんどの場合、デフォルト値1が適切ですが、異なるクラスの画像が小さな特徴のみで区別可能な場合(たとえば、小麦粉と塩のような粒状の材料)、このパラメータの値を増やすと分類の結果が向上するかもしれません。
モデルの使用
分類を実行する前に、DL_ClassifyObject_Deployフィルターを使用してモデルをロードする必要があります。代替として、モデルはDL_ClassifyObjectフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。

これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するには、inRoi入力を使用できます。
- 分類の結果は、outClassNameおよびoutClassIndex出力に渡されます。
- スコア値outScoreは分類の信頼度を示します。
5. インスタンスセグメンテーション
この技術は、画像内の1つまたは複数のオブジェクトを位置付け、セグメント化し、分類するために使用されます。この技術の結果は、検出されたオブジェクトの境界ボックス、マスク(セグメント化された領域)、クラスID、名前、メンバーシップ確率を記述する要素のリストです。
インスタンスセグメンテーションは、特徴検出技術とは異なり、個々のオブジェクトを検出し、それらが触れていたり重なっていたりしてもそれらを分離できるかもしれません。一方で、インスタンスセグメンテーションは、オブジェクトのような境界を持たない可能性がある傷やエッジなどの特徴を検出するための適切なツールではありません。

元の画像 |

視覚化されたインスタンスセグメンテーションの結果 |
トレーニングデータ
トレーニングフェーズでは、ユーザーは画像上のオブジェクトに対応する領域を描画し、それらをクラスに割り当てる必要があります。
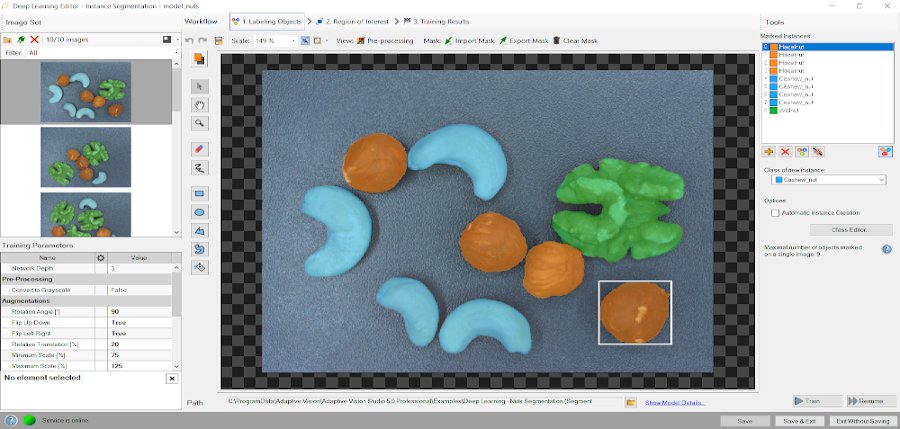
オブジェクトをマークするためのエディタ。
トレーニングパラメータ
インスタンスセグメンテーションのトレーニングは、ユーザーが提供したデータに適応し、デフォルトのパラメータ以外は必要ありません。
モデルの使用
モデルは、DL_SegmentInstances_Deployフィルターを使用してロードする必要があります。その後、DL_SegmentInstancesフィルターを使用して分類を実行します。代替として、モデルはDL_SegmentInstancesフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。


これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するには、inRoi入力を使用できます。
- 最小の検出スコアを設定するには、inMinDetectionScoreパラメータを使用できます。
- 単一の画像で検出されるオブジェクトの最大数は、inMaxObjectsCountパラメータで設定できます。デフォルトでは、トレーニングデータのオブジェクトの最大数と同じです。
- 検出されたオブジェクトを記述する結果は、次の出力に渡されます:
- 境界ボックス:outBoundingBoxes、
- クラスID:outClassIds、
- クラス名:outClassNames、
- 分類スコア:outScores、
- マスク:outMasks。
6. ポイントロケーション
この技術は、画像内の主要なポイント、特徴的な部分、および小さなオブジェクトを正確に特定および分類するために使用されます。この技術の結果は、対応するクラスの予測されたポイントの位置と、クラスの予測と信頼スコアのリストです。
インスタンスセグメンテーションの代わりにポイントロケーションを使用する場合:
- 厳密な位置の主要なポイントおよび厳密な境界のない特徴領域、
- セグメンテーションマスクや境界ボックスが必要ない場合のオブジェクト(おそらく非常に小さい)の位置と分類(オブジェクトの数え上げなど)。
フィーチャ検出の代わりにポイントロケーションを使用する場合:
- 主要なポイント、特徴的な領域の重心、オブジェクトなどの座標が必要な場合。

元の画像 |

視覚化されたポイントロケーションの結果 |
トレーニングデータ
トレーニングフェーズでは、ユーザーはトレーニング画像上の適切なクラスのポイントをマークする必要があります。
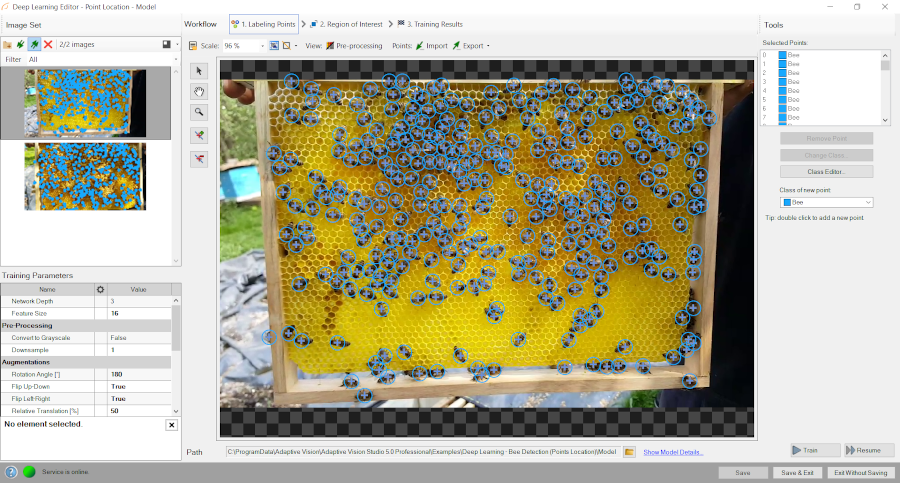
ポイントをマークするエディタ
フィーチャサイズ
Point Locationツールの場合、Feature Sizeパラメータはオブジェクトまたは特徴的な部分のサイズに対応します。画像に異なるスケールのオブジェクトが含まれている場合、Feature Sizeは平均オブジェクトサイズよりもわずかに大きい値を使用することをお勧めしますが、最適な結果を得るために異なる値で実験する必要があります。
パフォーマンスのヒント:フィーチャサイズが64ピクセルを超え、まだ小さすぎると見える場合は、Downsampleオプションを検討する価値があります。
モデルの使用
モデルは、DL_LocatePoints_Deployフィルターを使用してロードする必要があります。その後、DL_LocatePointsフィルターを使用してポイントの位置と分類を実行します。代替として、モデルはDL_LocatePointsフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。


これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するには、inRoi入力を使用できます。
- 最小検出スコアを設定するには、inMinDetectionScoreパラメータを使用できます。
- inMinDistanceRatioパラメータを使用して、異なると見なされる2つのポイント間の最小距離を設定できます。距離はMinDistanceRatio * FeatureSizeで計算されます。この値が有効でない場合、最小距離はトレーニングデータに基づきます。
- 検出速度を向上させるが、ポテンシャルにやや悪い精度になる可能性がある場合は、inOverlapをFalseに設定できます。
- 検出されたポイントを記述する結果は、次の出力に渡されます:
- ポイント座標:outLocations、
- クラスID:outClassIds、
- クラス名:outClassNames、
- 分類スコア:outScores。
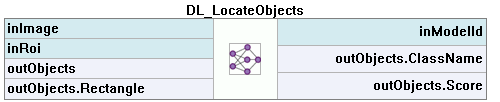
7. オブジェクトの位置特定
この技術は、画像内の1つまたは複数のオブジェクトの位置を特定および分類するために使用されます。この技術の結果は、予測されたオブジェクトを境界で囲む矩形のリストで、対応するクラスの予測と信頼スコアが含まれています。
このツールは、予測されたオブジェクトを含む矩形領域を返し、そのおおよその位置と方向を示しますが、オブジェクトの主要なポイントやセグメンテーション領域の正確な位置は返しません。これは、ポイントロケーションとインスタンスセグメンテーションの中間的な解決策です

元の画像 |

視覚化されたオブジェクトの位置特定の結果 |
トレーニングデータ
トレーニングフェーズでは、ユーザーはトレーニング画像上の適切なクラスのオブジェクトを境界で囲む矩形をマークする必要があります。
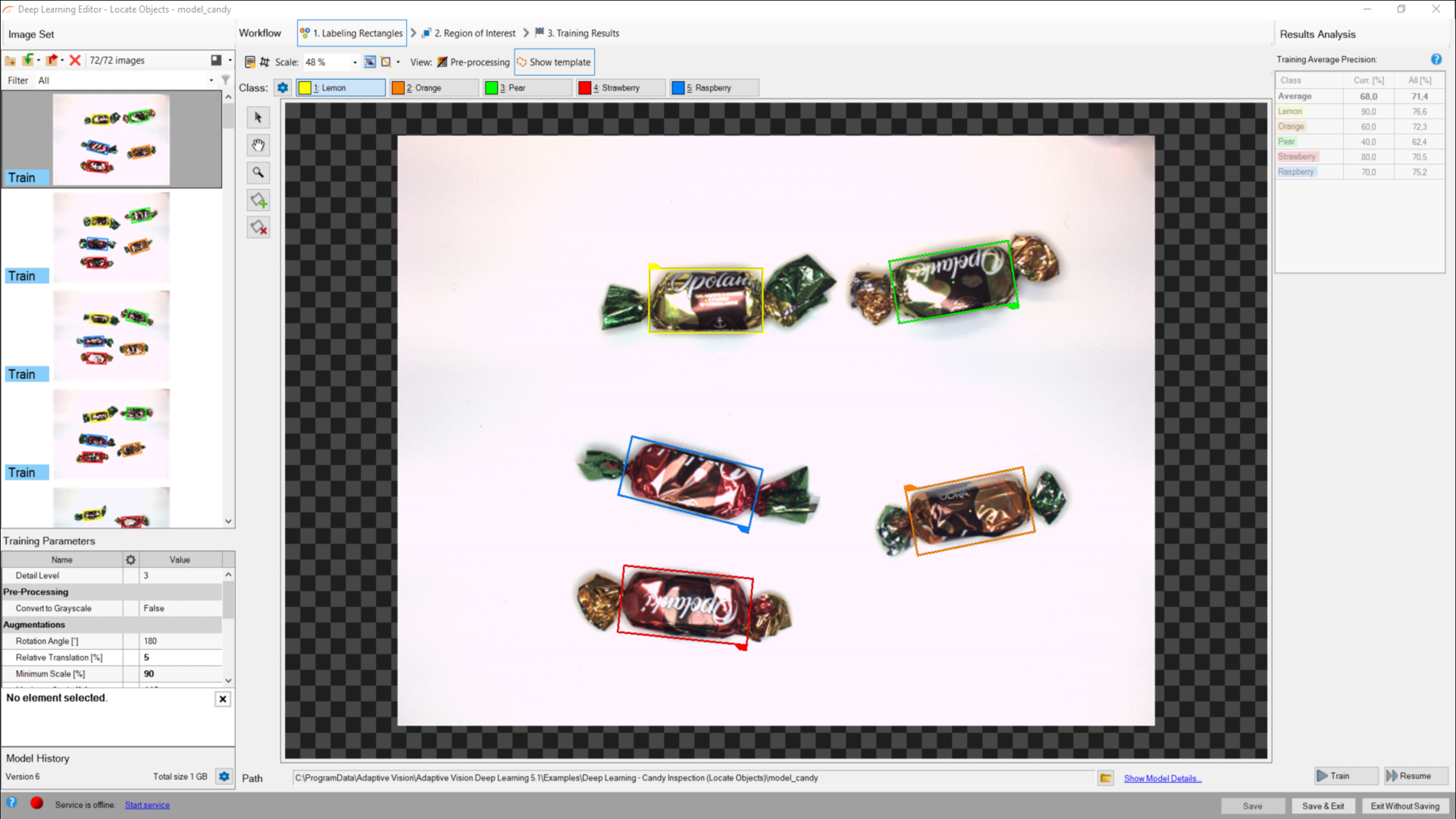
オブジェクトをマークするエディタ
モデルの使用
モデルは、DL_LocateObjects_Deployフィルターを使用してロードする必要があります。その後、DL_LocateObjectsフィルターを使用してオブジェクトの位置特定と分類を実行します。代替として、モデルはDL_LocateObjectsフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。

これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するには、inRoi入力を使用できます。
- 最小検出スコアを設定するには、inMinDetectionScoreパラメータを使用できます。
- 検出されたオブジェクトを記述する結果は、オブジェクト出力に渡されます:outObjects。
8. 文字の読み取り
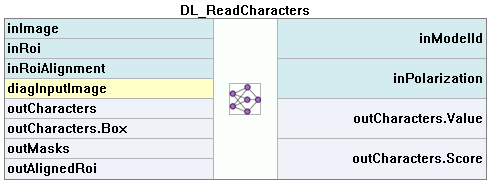
この技術は、画像内の文字を特定および認識するために使用されます。結果は見つかった文字のリストです。
このツールは事前にトレーニングされたモデルを使用し、トレーニングできません。

元の画像 |

読み取られた文字の視覚化された結果 |
モデルの使用
モデルは、DL_ReadCharacters_Deployフィルターを使用してロードする必要があります。その後、DL_ReadCharactersフィルターを使用して認識を実行します。代替として、モデルはDL_ReadCharactersフィルターで直接ロードできますが、最初のイテレーションにははるかに長い時間がかかります。

これらのフィルターと同時にAurora Vision Deep Learning Serviceを実行することはお勧めされません。性能が低下するか、エラーが発生する可能性があります。
パラメータ:
- 画像解析の範囲を制限するか、テキストの方向を設定するには、inRoi入力を使用できます。
- 分析領域内の文字の平均サイズ(ピクセル単位)は、inCharHeightパラメータで設定する必要があります。
- 非常に細かいまたは広い文字を持つフォントでパフォーマンスを向上させるには、inWidthScale入力を使用できます。ある程度では、文字が非常に近くにある場合にも役立つかもしれません。
- 認識される文字のセットを制限するには、inCharRangeパラメータを使用します。
9. トラブルシューティング
以下は、最も一般的な問題のリストです。
1. ネットワークの過学習
ネットワークが利用可能な問題に対する一般的な能力を失い、テストデータだけに焦点を当てる状況。
症状:トレーニング中、検証グラフがあるレベルで停止し、トレーニンググラフが続行されます。トレーニング画像の欠陥は非常に正確にマークされますが、新しい画像の欠陥はあまりよくマークされません。
ネットワークの過学習に特有のグラフ。
原因:
- テストサンプルの数が少なすぎる。
- トレーニング時間が長すぎます。
可能な解決策:
- 異なるオブジェクトの本物のサンプルを提供します。
- より多くの拡張を使用します。
- ネットワークの深さを減らします。
2. 光条件の変化への感受性
症状:微小な光の変化でも、ネットワークが画像を正しく処理できません。
原因:
- 変動する照明条件のサンプルが提供されていない。
解決策:
- 変動する照明のサンプルを提供します。
- 自動照明の拡張のために「Luminance」オプションを有効にします。
3. ネットワークトレーニングで進捗がない
症状 ― トレーニング時間が最適であっても、トレーニングの進捗が見られません。

矛盾するサンプルでのトレーニング進捗
原因:
- サンプルの数が少なすぎるか、サンプルが十分に変動していない。
- 画像のコントラストが小さすぎる。
- 選択したネットワークアーキテクチャが小さすぎる。
- 欠陥のマスクに矛盾がある。
解決策:
- 欠陥を露出させるために照明を変更します。
- 欠陥のマスクでの矛盾を解消します。
ヒント:特定のタイプの欠陥のすべてを入力画像でマークするか、マークされていない欠陥の画像を削除することを忘れないでください。特定のタイプの欠陥の一部だけをマークすると、ネットワークの学習プロセスに悪影響を及ぼす可能性があります。
4. トレーニング/サンプル評価が非常に遅い
症状 ― トレーニングまたはサンプル評価には多くの時間がかかります。
原因:
- 提供された入力画像の解像度が高すぎる。
- 欠陥を含まない可能性のあるフラグメントも分析されています。
解決策:
- 画像の解像度を減少させるために「Downsample」オプションを有効にします。
- サンプル評価のためにROIを制限します。
- より低いネットワークの深さを使用します。
関連項目
- ディープラーニングサービスの構成 - ディープラーニングサービスのインストールおよび構成,
- ディープラーニングモデルの作成 - ディープラーニングエディターの使用方法。